














MLOps in 2026: Best Practices for Scalable Machine Learning Deployment
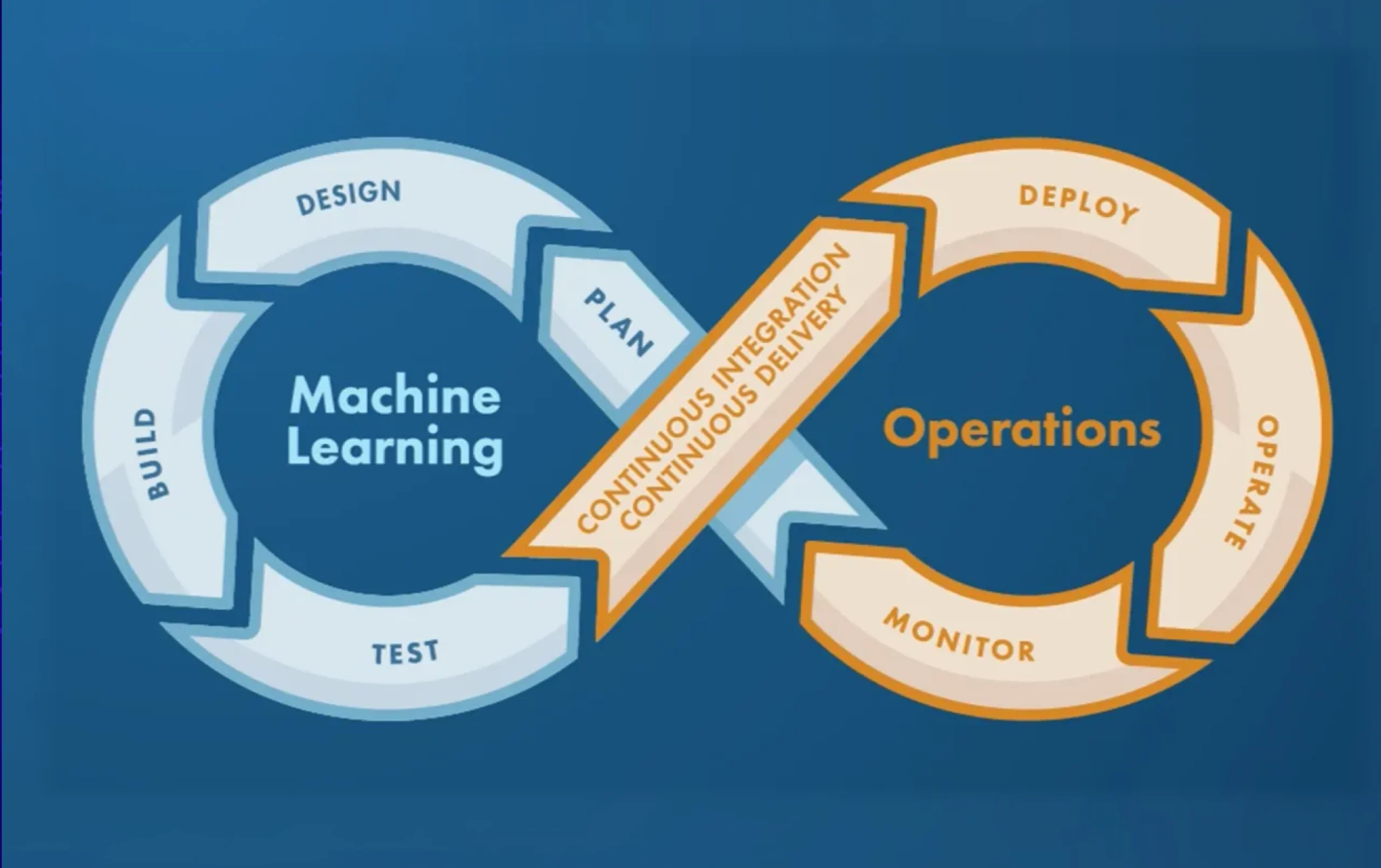
Machine Learning (ML) has moved far beyond experimentation. In 2026, enterprises are no longer asking “Can we build ML models?” – they are asking “How do we deploy, scale, monitor, and govern ML models reliably in production?”
This is where MLOps (Machine Learning Operations) becomes critical.
In simple terms: MLOps (Machine Learning Operations) is the discipline of automating and operationalizing the full machine learning lifecycle — from data ingestion and model training through deployment, monitoring, and retraining — applying DevOps engineering principles to ML systems. The goal is to deploy ML models reliably, monitor their performance in production, and keep them accurate as real-world data changes over time.
Despite massive investments in AI, many organizations still struggle to operationalize ML models. Models work well in notebooks, but fail in real-world environments due to data drift, infrastructure bottlenecks, lack of monitoring, or governance gaps. According to industry studies, a significant percentage of ML models never make it to production – and even fewer deliver sustained business value.
In 2026, MLOps is no longer optional. It is the foundation that enables scalable, secure, compliant, and business-ready AI systems.
This guide explores what MLOps looks like in 2026, why it matters, common challenges, and best practices enterprises must adopt to deploy ML at scale.
1. What Is MLOps and Why It Matters More in 2026
MLOps is a set of practices, tools, and processes that unify machine learning development (ML) with IT operations (Ops). It ensures that ML models can be built, tested, deployed, monitored, and improved continuously in production.
In 2026, MLOps has evolved beyond basic CI/CD for models. It now covers:
-
- Model lifecycle management
- Data versioning and governance
- Continuous training and retraining
- Infrastructure automation
- Monitoring, observability, and compliance
- Integration with enterprise systems
Why MLOps Is Business-Critical in 2026
Several trends have made MLOps indispensable:
-
- Explosion of ML use cases across customer experience, healthcare, finance, supply chain, and operations
- Rise of Generative AI and foundation models, increasing model complexity
- Stricter regulations around data privacy, explainability, and AI governance
- Need for real-time ML systems with low latency and high availability
- Enterprise demand for ROI, not just experiments
Without MLOps, organizations face fragile deployments, unpredictable model behavior, and rising operational costs.
2. How MLOps Has Evolved from 2020 to 2026
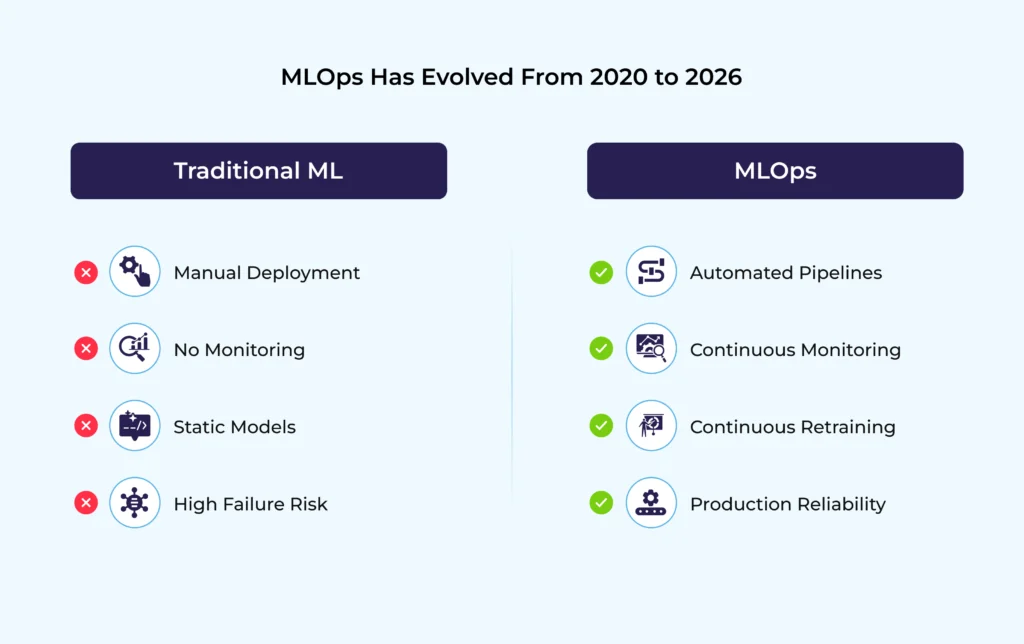
Early MLOps focused mainly on deploying models using basic pipelines. In 2026, MLOps has matured into a full enterprise discipline.
Then (Traditional MLOps)
-
- Manual model deployment
- Limited monitoring
- Static models trained once
- Little to no governance
- Weak collaboration between data science and IT
Now (Modern MLOps in 2026)
-
- End-to-end automated pipelines
- Continuous training and evaluation
- Model observability and explainability
- Scalable cloud-native infrastructure
- Security, compliance, and audit readiness
- Alignment with business KPIs
Modern MLOps treats ML models as living systems, not one-time artifacts.
3. Core Components of an Enterprise-Grade MLOps Architecture
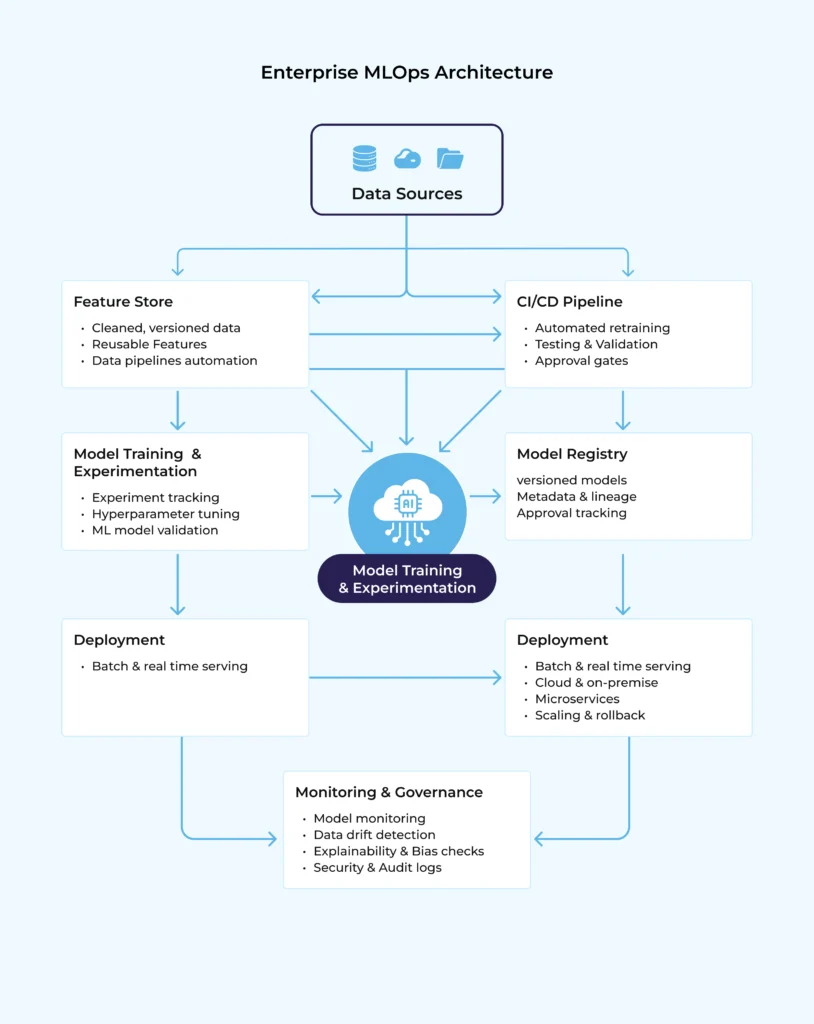
To deploy ML at scale in 2026, enterprises need a structured MLOps architecture.
- Data Layer
-
- Data ingestion pipelines
- Data validation and quality checks
- Feature stores for reuse and consistency
- Data versioning and lineage tracking
Clean, reliable data is the backbone of successful ML systems.
- Model Development Layer
-
- Experiment tracking
- Model versioning
- Reproducible training environments
- Automated evaluation metrics
This ensures data scientists can iterate quickly while maintaining reproducibility.
- CI/CD for Machine Learning
Unlike traditional software, ML pipelines must handle:
| Model retraining | Feature changes |
| Data drift | Dependency updates |
CI/CD in MLOps automates:
| Training pipelines | Testing and validation |
| Deployment approvals | |
- Deployment Layer
Supports multiple deployment strategies:
| Batch inference | Real-time inference |
| Edge deployment | Hybrid cloud / on-prem models |
This layer must be scalable, fault-tolerant, and low latency.
- Monitoring & Observability
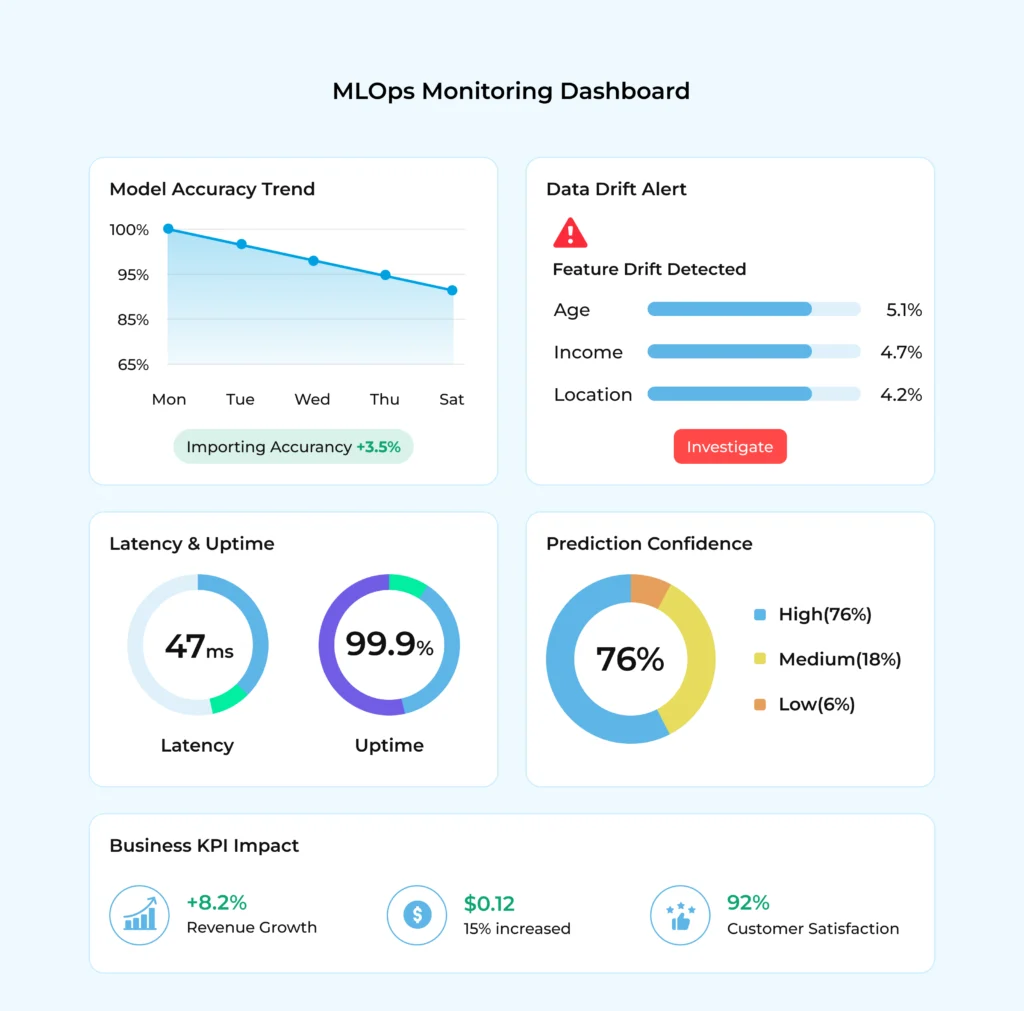
Modern MLOps monitors:
-
- Model performance
- Data drift and concept drift
- Latency and uptime
- Bias and fairness metrics
Monitoring is continuous, not post-failure.
- Governance & Security Layer
In 2026, enterprises must ensure:
-
- Explainability (XAI)
- Role-based access control
- Audit logs
- Regulatory compliance (GDPR, HIPAA, etc.)
Governance is embedded into MLOps, not added later.
4. Best Practices for Scalable ML Deployment in 2026
-
Treat ML Pipelines as First-Class Software
ML systems should follow the same rigor as production software:
-
- Version control for data, code, and models
- Automated testing for features and outputs
- Modular, reusable pipelines
This eliminates fragile deployments and “black-box” models.
-
Automate the Entire Model Lifecycle
Manual intervention is the biggest scalability bottleneck.
Enterprises should automate:
-
- Data ingestion
- Feature engineering
- Model training
- Validation and approval
- Deployment and rollback
Automation reduces errors, speeds up delivery, and improves reliability.
-
Use Feature Stores for Consistency
Feature mismatch between training and production is a common failure point.
Feature stores ensure:
-
- Consistent feature definitions
- Reuse across teams
- Real-time and batch availability
In 2026, feature stores are essential for enterprise ML scalability.
-
Implement Continuous Monitoring and Drift Detection
Models degrade over time due to:
-
- Data distribution changes
- Customer behavior shifts
- Market dynamics
Best-in-class MLOps systems detect:
-
- Data drift
- Prediction drift
- Performance decay
Automated retraining pipelines keep models accurate and relevant.
-
Design for Scalability from Day One
Scalable ML deployment requires:
-
- Containerization (Docker, Kubernetes)
- Auto-scaling inference services
- Load balancing and failover mechanisms
Cloud-native design ensures ML systems can handle peak demand without manual intervention.
-
Align MLOps Metrics with Business KPIs
Technical accuracy alone is not enough.
In 2026, successful MLOps tracks:
| Revenue impact | Cost reduction |
| Customer satisfaction | Operational efficiency |
This alignment ensures ML investments deliver measurable ROI.
-
Build Security and Compliance into Pipelines
Security is not optional for enterprise AI.
MLOps pipelines should include:
| Data encryption | Access controls |
| Secure model artifacts | Audit logs |
For regulated industries, compliance must be continuous and automated.
5. Common MLOps Challenges Enterprises Face
Despite advancements, organizations still face obstacles:
- Siloed Teams
Data scientists, engineers, and IT teams often work in isolation, slowing deployment.
Solution: Cross-functional MLOps teams with shared ownership.
- Model Sprawl
Too many models without proper tracking lead to chaos.
Solution: Centralized model registry and lifecycle governance.
- Lack of Observability
Many teams only notice problems after users complain.
Solution: Proactive monitoring with alerts and dashboards.
- Infrastructure Complexity
Scaling ML workloads is expensive and complex.
Solution: Cloud-native MLOps platforms with auto-scaling.
6. MLOps for Generative AI and LLMs in 2026
Generative AI has introduced new operational challenges:
-
- Large model sizes
- High compute costs
- Prompt and response management
- Hallucination risks
Modern MLOps for GenAI includes:
-
- Prompt versioning
- Evaluation pipelines for outputs
- RAG (Retrieval-Augmented Generation) integration
- Cost and latency monitoring
MLOps now supports models, prompts, data, and agents — not just algorithms.
7. Industry Use Cases Driving MLOps Adoption
Healthcare
| Predictive diagnostics | Clinical decision support |
| Workflow automation | |
Requires strict governance and explainability.
Finance
| Fraud detection | Credit scoring |
| Risk modelling | |
Demands real-time inference and regulatory compliance.
Retail & E-commerce
| Recommendation engines | Demand forecasting |
| Dynamic pricing | |
Needs scalability during peak traffic.
Manufacturing
| Predictive maintenance | Quality inspection |
| Supply chain optimization | |
Relies on edge deployment and IoT integration.
8. Build vs Buy: Choosing the Right MLOps Approach
Off-the-Shelf MLOps Platforms
Pros:
-
- Faster setup
- Managed infrastructure
Cons:
-
- Limited customization
- Vendor lock-in
Custom MLOps Frameworks
Pros:
-
- Tailored to business needs
- Full control and security
- Better integration
Cons:
-
- Requires expertise
In 2026, many enterprises adopt hybrid MLOps strategies — combining managed tools with custom pipelines.
9. The Future of MLOps Beyond 2026
MLOps will continue to evolve into:
-
- AgentOps: Managing autonomous AI agents
- Self-healing ML systems
- AI governance by design
- Unified AI operations platforms
- Tighter integration with business workflows
MLOps will become the operating system for enterprise AI.
Why MLOps Is the Backbone of Scalable AI
In 2026, machine learning success is not defined by model accuracy — it is defined by reliability, scalability, governance, and business impact.
 MLOps enables organizations to:
MLOps enables organizations to:
-
- Deploy ML models faster
- Scale AI across departments
- Reduce operational risk
- Ensure compliance and trust
- Maximize ROI from AI investments
Enterprises that invest in strong MLOps foundations today will be the ones that lead the AI-driven economy tomorrow.
Key Takeaway
This article addresses the 2026 reality that ‘building ML models’ is no longer the hard part — reliable production operation is. It covers the seven MLOps best practices most commonly missing from enterprise ML deployments: automated ML pipelines (CI/CD/CT), model versioning and registry, data drift detection, automated retraining triggers, model explainability for governance, cost optimization for LLM inference, and LLMOps extensions for Generative AI. Tools covered include MLflow, Kubeflow, Evidently AI, Langsmith, and Weights & Biases.



