














RAG vs Traditional AI – Why It Matters for the Future of AI
Artificial Intelligence (AI) has rapidly evolved in the last few years, with Large Language Models (LLMs) like GPT, Claude, and LLaMA revolutionizing how humans interact with technology. These models can draft emails, summarize research papers, write code, and even hold human-like conversations. But despite their power, traditional LLMs have limitations: they rely on fixed training data and sometimes produce hallucinations—answers that sound correct but are factually wrong.
Parametric Knowledge:
Knowledge that has been encoded into an LLM’s weights during training — the model ‘knows’ something because it was present in training data, not because it is retrieved at query time. Parametric knowledge is static (fixed at training cutoff), cannot be updated without retraining, and cannot provide citations.
Non-parametric Knowledge:
Knowledge that exists outside the LLM’s weights and is retrieved at query time — the knowledge base, vector database, or documents that RAG retrieves from. Non-parametric knowledge can be updated without retraining the model, can be cited with source documents, and can contain private organizational data.
Knowledge Cutoff:
The date after which an LLM has no training data — events, publications, or developments after this date are unknown to the model. GPT-4’s knowledge cutoff is early 2024; Claude’s varies by version. RAG eliminates the knowledge cutoff problem by retrieving current information at query time.
Open-Book vs Closed-Book AI:
An analogy for RAG vs traditional LLM: a closed-book AI answers from memorized knowledge (training data) alone — like a student answering an exam with no reference materials. An open-book AI (RAG) can consult reference materials (retrieved documents) when answering — leading to more accurate, verifiable, and up-to-date responses.
To address these challenges, researchers developed Retrieval-Augmented Generation (RAG). Unlike conventional LLMs that depend only on their training knowledge, RAG integrates external data sources into the generation process, creating responses that are not only fluent but also grounded in real, verifiable facts.
In this blog, we’ll compare Traditional AI (LLMs) vs RAG, explore their differences, strengths, weaknesses, and explain why RAG is shaping the future of AI applications in enterprises and beyond.
What is Traditional AI (LLMs)?
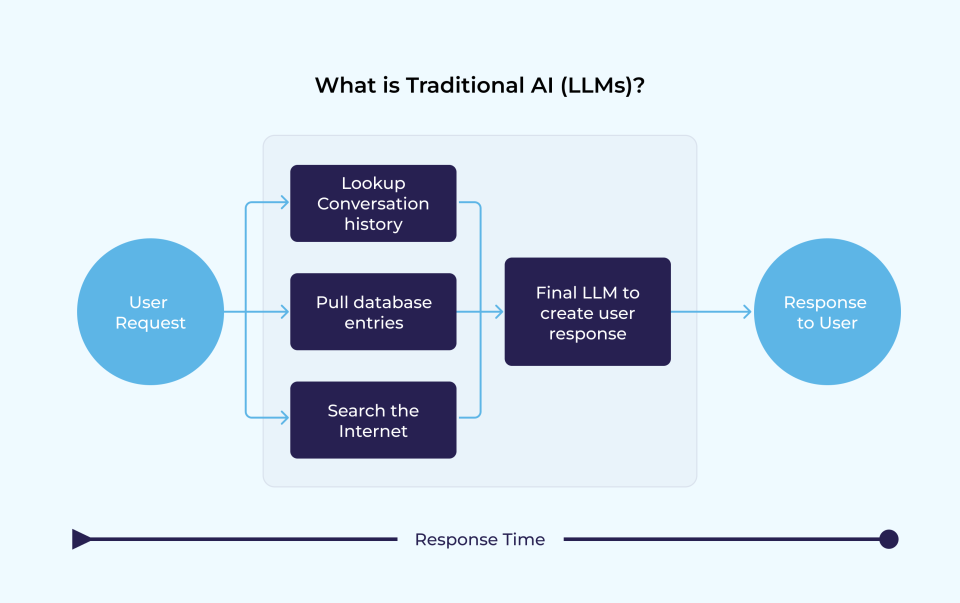
Traditional AI, in this context, refers to standalone Large Language Models (LLMs) trained on massive datasets of text, code, and human interactions. Using this training, they learn language patterns and generate responses based on probability.
For example, if you ask a traditional AI (LLMs):
“What is the capital of Australia?”
-
- It will respond with “Canberra” because that fact was likely included in its training data.
- But if you ask about a company’s 2024 annual report (which the model hasn’t seen during training), the LLM might make a best guess—and get it wrong.
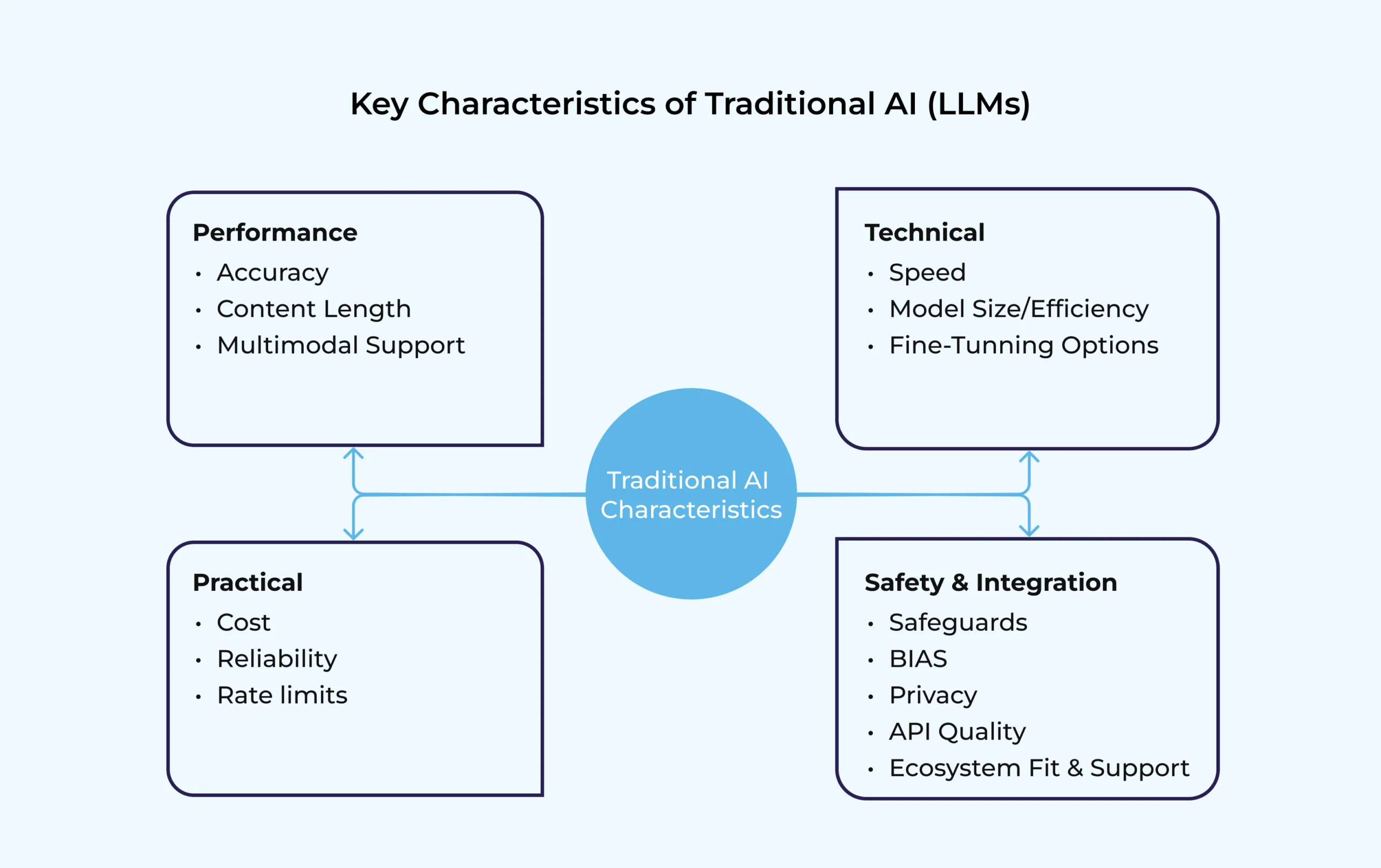
Key Characteristics of Traditional AI (LLMs):
-
- Knowledge is static (limited to training data).
- Updating requires retraining or fine-tuning—expensive and resource-heavy.
- Risk of hallucinations when asked about topics outside training scope.
- Great at language fluency, reasoning, and general-purpose tasks.
What is Retrieval-Augmented Generation (RAG)?
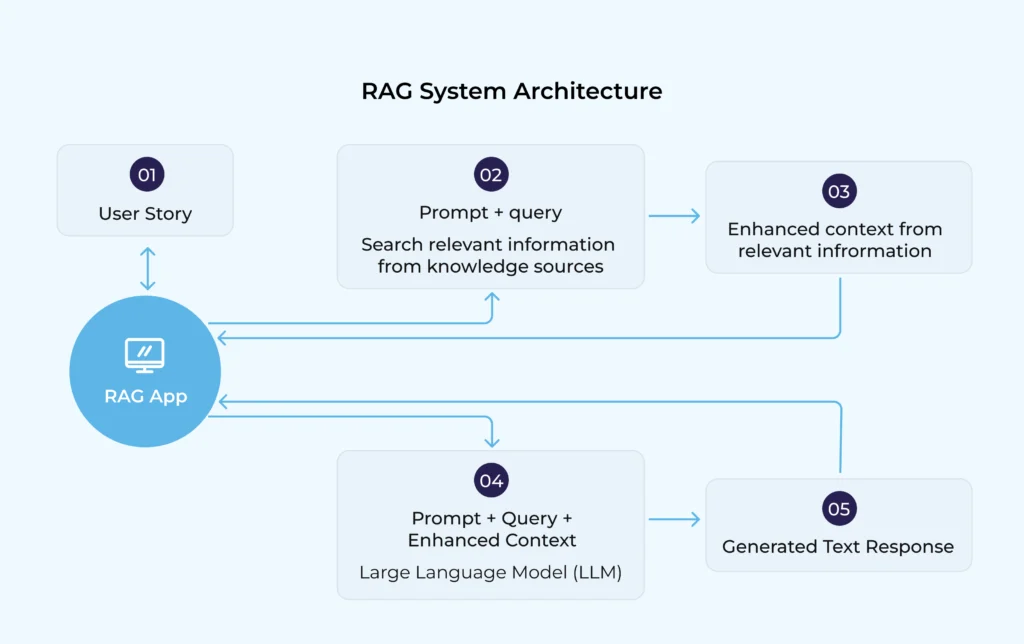
RAG (Retrieval-Augmented Generation) enhances LLMs by integrating a retrieval mechanism. Instead of relying only on pre-trained knowledge, RAG searches external databases (like company documents, policies, medical research, or real-time news) before generating answers.
In other words, RAG is like giving the AI access to a library or search engine—it first retrieves relevant information and then uses the LLM to craft a natural, conversational response.
Key Characteristics of RAG:
-
- Dynamic knowledge access (always up-to-date).
- No retraining needed—new data can be added instantly.
- Reduces hallucinations by grounding responses in verified sources.
- Suitable for enterprise-specific applications (e.g., healthcare guidelines, financial compliance, technical manuals).
RAG vs Traditional AI (LLMs): A Side-by-Side Comparison

|
Feature |
Traditional AI (LLMs) |
RAG (Retrieval-Augmented Generation) |
| Knowledge Base | Static (limited to training data) | Dynamic (connects to external sources) |
| Accuracy | Prone to hallucinations | More accurate, grounded in facts |
| Updates | Requires retraining or fine-tuning | Instantly updates via database indexing |
| Customization | Hard to specialize for organizations | Easy to tailor with company-specific data |
| Cost & Maintenance | Expensive to update | Lower cost, scalable |
| Use Cases | General-purpose tasks, creative writing | Mission-critical domains (healthcare, legal, finance, enterprise knowledge management) |
A Practical Example
Scenario: Customer asks an AI assistant
Question: “What is our company’s warranty policy for laptops purchased in 2024?”
-
- Traditional AI (LLMs):
It may guess based on generic warranty information it learned during training. The answer could be vague, outdated, or incorrect. - RAG-enabled AI:
It retrieves the latest warranty policy from the company’s database and responds:
“According to the 2024 warranty policy, all laptops come with a 2-year limited warranty covering hardware defects but excluding accidental damage.”
- Traditional AI (LLMs):
The difference? Accuracy, trust, and compliance.
Why Traditional AI (LLMs) Aren’t Enough Anymore
While LLMs were groundbreaking, enterprises face several challenges when relying solely on them:
-
- Hallucinations Erode Trust: Users quickly lose confidence in AI when it confidently gives wrong answers. In regulated industries, this can even lead to legal or compliance risks.
- Knowledge Quickly Becomes Outdated: An LLM trained in 2023 won’t know about 2025 events unless it’s retrained – a costly process.
- Limited Enterprise Use Cases: Companies want AI that understands their documents, policies, and workflows. A generic model trained on the internet can’t fully deliver this without augmentation.
Why RAG is the Future of AI
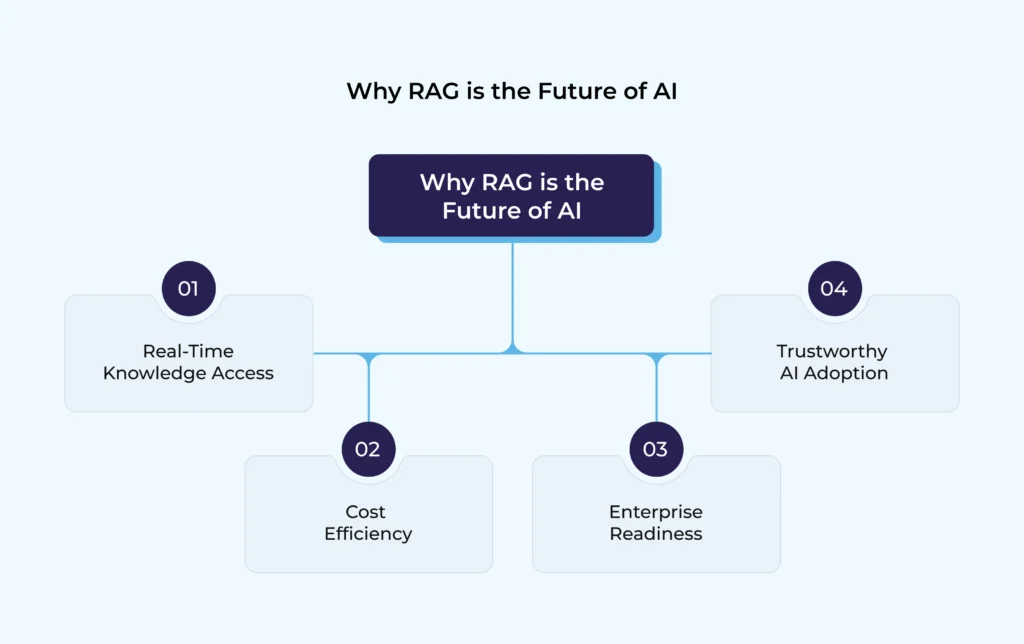
RAG addresses the shortcomings of traditional AI (LLMs) and unlocks new opportunities. Here’s why it matters:
-
- Real-Time Knowledge Access
- Connects AI to external databases, APIs, or even the web.
- Ensures responses are always up-to-date.
- Cost Efficiency
- No need for expensive fine-tuning or retraining.
- Just add or update documents in the knowledge base.
- Enterprise Readiness
- Perfect for sectors like healthcare, law, finance, and customer service where accuracy is critical.
- Trustworthy AI Adoption
- Builds confidence by reducing hallucinations and providing source-backed answers.
- Real-Time Knowledge Access
Use Cases: Where RAG Outperforms Traditional AI LLMs
-
- Healthcare: Accurate medical guidance based on the latest research and treatment guidelines.
- Legal Services: Retrieval of laws, precedents, and case documents instead of generic responses.
- Financial Services: Real-time compliance answers based on regulatory databases.
- Customer Support: Company-specific FAQs and policies for instant and precise assistance.
- Enterprise Knowledge Management: Employees can query internal documents and get verified answers.
Challenges in Implementing RAG
While RAG is powerful, businesses must consider some challenges:
-
- Data Quality – Garbage in, garbage out. If documents are outdated or incorrect, the AI will return flawed results.
- Infrastructure Needs – Setting up embeddings, vector databases, and retrievers requires technical expertise.
- Latency – Searching and retrieving from large knowledge bases may add slight delays, though optimizations exist.
Despite these hurdles, the benefits of accuracy, adaptability, and scalability make RAG a must-have for future AI systems.
The Future: Hybrid AI with RAG at Its Core
Looking ahead, AI systems will likely evolve into hybrid models where RAG is standard. Some trends to expect:
-
- Multi-Modal RAG: Retrieval not just from text, but also images, audio, and video.
- Explainable RAG: AI will cite sources for greater transparency.
- Domain-Specific RAG Solutions: Tailored models for industries like healthcare, law, or engineering.
- Smarter Retrieval Algorithms: Faster, more accurate matching of queries to knowledge sources.
In short, RAG will be the bridge between raw AI power and real-world reliability.

Key Takeaway
-
- Traditional LLMs are excellent at reasoning and language generation but have a fundamental limitation: knowledge fixed at training time.
- RAG extends LLMs with dynamic, retrievable knowledge — transforming them from closed-book to open-book AI systems.
- For enterprise applications requiring accuracy on specific organizational data, RAG consistently outperforms standalone LLMs.
- RAG is not a replacement for LLM capability — it is an architectural enhancement that gives LLMs better information to reason from.
- The future of enterprise AI is hybrid: RAG for factual grounding + LLM reasoning for synthesis, planning, and generation.
- Fine-tuning and RAG are complementary — RAG for dynamic knowledge, fine-tuning for domain-specific style and reasoning patterns.



