














What is Retrieval-Augmented Generation (RAG) in AI? A Beginner’s Guide

Artificial Intelligence (AI) has come a long way in recent years. Models like ChatGPT, GPT-4, and other Large Language Models (LLMs) are capable of writing essays, answering questions, and even generating code. But there’s a problem: they don’t always get it right.
Sometimes these models confidently provide answers that are completely false—a phenomenon experts call hallucination. In casual use, a made-up answer might be harmless, but in fields like healthcare, finance, or legal services, a wrong response can have serious consequences.
This is where RAG (Retrieval-Augmented Generation) steps in. It’s a technique designed to make AI both smarter and safer by giving it access to the right information at the right time.
The Core Idea of RAG
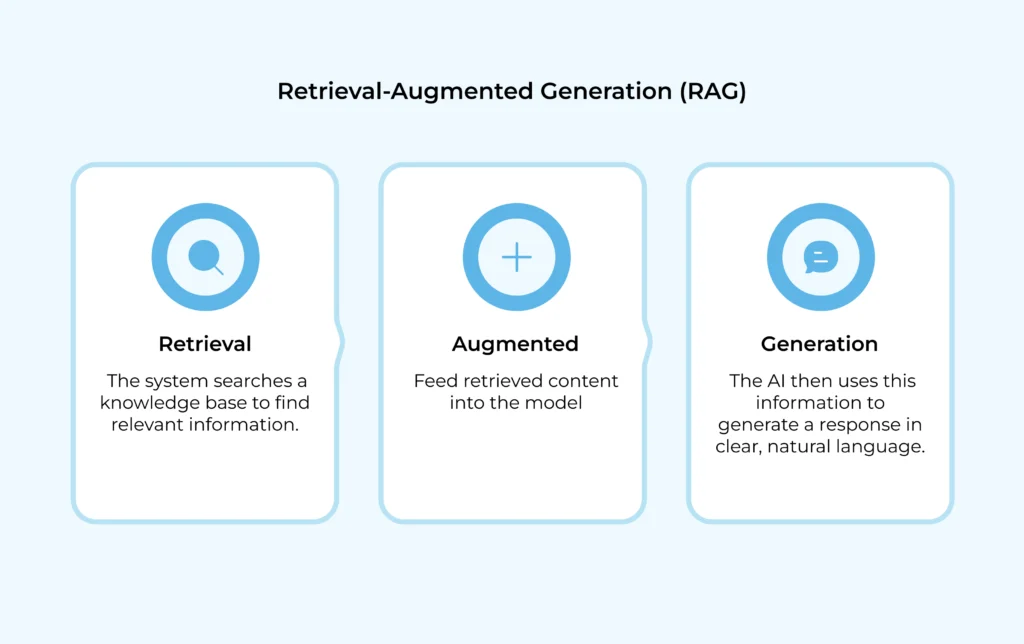
At its heart, RAG combines two capabilities: retrieval and generation.
-
- Retrieval: The AI first searches a trusted knowledge source, like a database, company documents, or a vector store, to find the most relevant information.
- Generation: Once the facts are retrieved, the AI generates a natural, conversational response based on that information.
This makes RAG a hybrid approach. Instead of relying only on what the model learned during training, it can now “look things up” before answering—just like how humans check a book, a website, or notes before responding.
An Analogy to Make It Simple
Imagine you’re in a library and someone asks you a question: “What’s the process to renew a passport?”
-
- Without RAG, you’d rely on memory alone. You might remember most of the details, but you could mix up timelines, forms, or requirements.
- With RAG, you’d first pull the official government handbook from the shelf (retrieval), then explain the process clearly in your own words (generation).
That’s exactly how RAG works—accuracy from facts, combined with the fluency of AI language models.
How RAG Works (Step by Step)
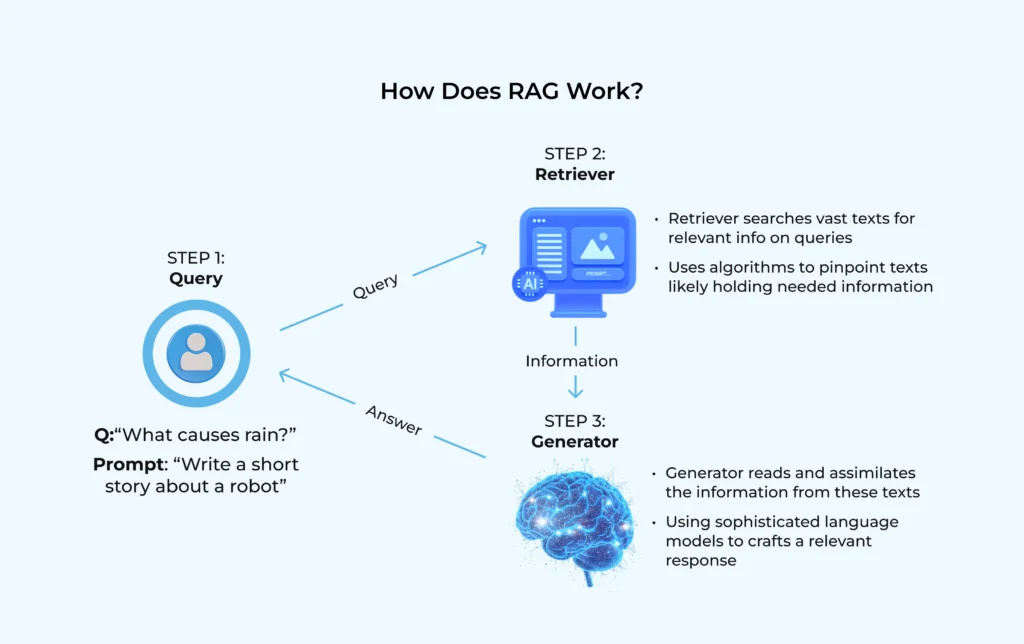
To understand RAG more deeply, let’s break down the workflow:
-
- User Query: The process begins when a user asks a question, like “What’s the return policy for electronics?”
- Encoding and Search: The question is turned into a vector (a mathematical representation of its meaning). This vector is used to search a vector database that stores all company documents in the same format.
- Retriever Stage: The system pulls out the most relevant snippets or chunks of text, such as the section of a policy document that covers returns.
- Generator Stage: A language model takes those snippets and writes a clear, context-rich response in natural language.
- Final Answer: The user sees a reliable answer grounded in real company data, not a guess.
This process takes milliseconds but ensures that answers are both accurate and well-explained.
Why RAG Matters for AI
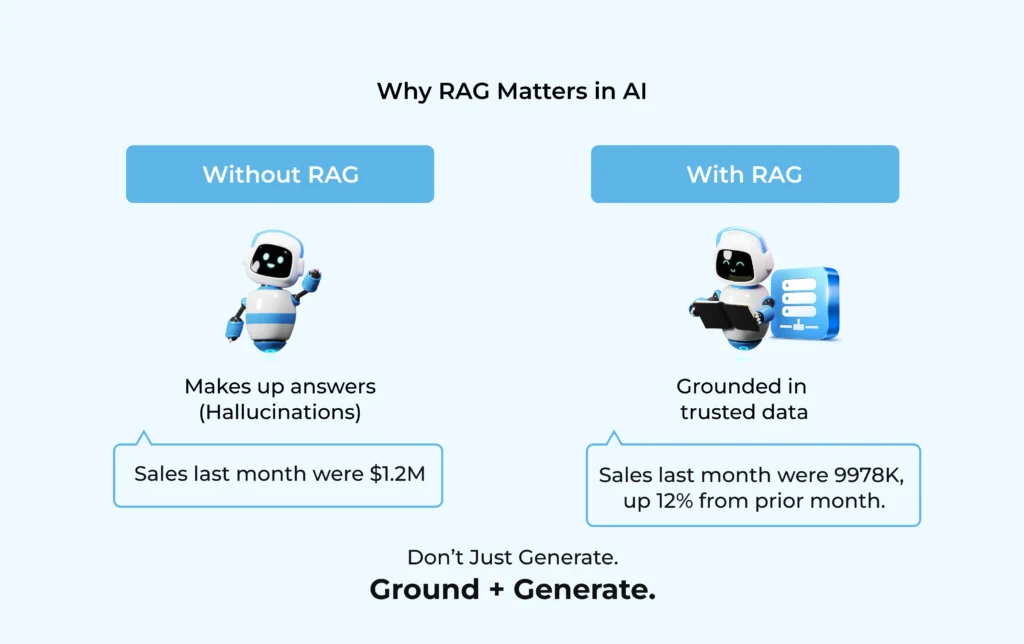
The rise of RAG is not just a technical improvement—it’s a shift in how AI can be trusted in real-world use cases.
-
- Accuracy: By grounding answers in facts, RAG reduces the chances of hallucination.
- Customization: Instead of answering with generic internet knowledge, AI can use your specific data—your policies, your manuals, your research papers.
- Cost Efficiency: Unlike fine-tuning, where you retrain a whole model, RAG lets you plug in new data easily without modifying the core model.
- Scalability: RAG works across domains—from customer support bots that answer questions using FAQs to enterprise assistants that search millions of documents instantly.
A Practical Example
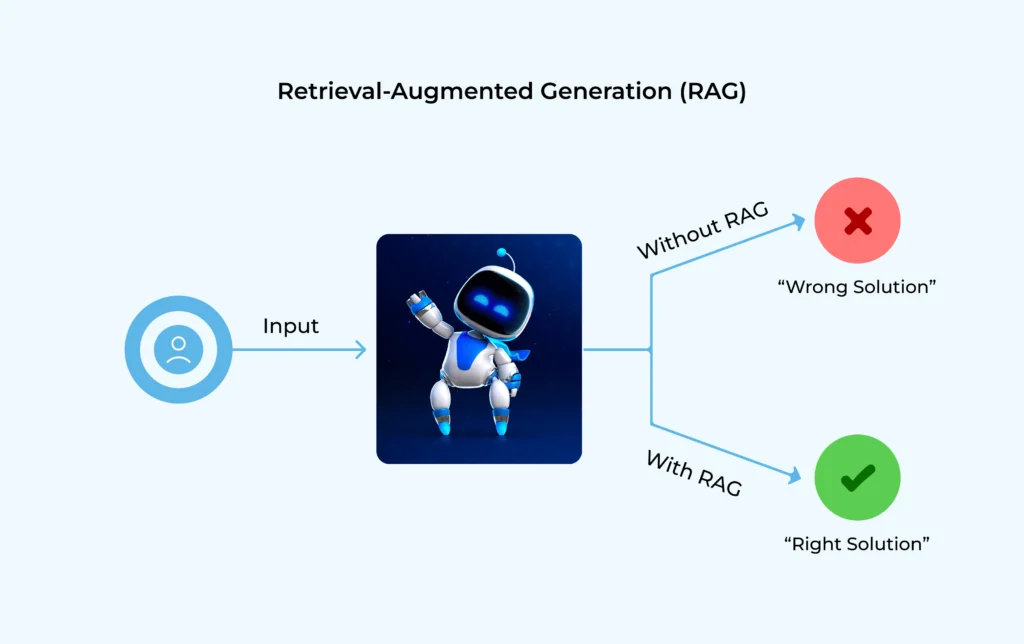
Let’s take an airline customer support chatbot as an example.
-
- A passenger asks: “Can I carry a power bank in my luggage?”
- Without RAG, a standard LLM might respond: “Yes, you can check it in.” ❌ Wrong and potentially dangerous.
- With RAG, the system retrieves the official baggage policy from the airline’s database and generates the correct response:
“According to airline policy, power banks are only allowed in hand baggage, not in checked luggage.” ✅
This is the difference between an AI that “sounds smart” and an AI that’s actually useful and reliable.
Where RAG is Being Used Today
RAG isn’t just a theory—it’s already powering real-world applications across industries:
-
- Healthcare: Helping doctors and patients find accurate information from medical guidelines.
- Finance: Assisting banks in answering customer queries with up-to-date compliance rules.
- Legal: Providing lawyers with case summaries grounded in actual documents, not hallucinated examples.
- Enterprise Search: Allowing employees to query internal company knowledge bases without reading through hundreds of PDFs.
The Takeaway
RAG is one of the most practical innovations in AI today. By combining retrieval (facts) and generation (language), it makes AI systems not just smarter, but also more trustworthy.
Think of it as giving AI the ability to look things up before speaking—something we humans naturally do. This simple shift has huge implications for businesses and users alike.
RAG turns AI from a “best guess machine” into a knowledge-powered assistant you can rely on.




