





Let’s Talk Business!
+1 817 380 5522
Let’s Connect


- All
- Languages
- Gen AI platforms
- Frameworks
- Debugging & Tracing
- Vector Databases
- DBMS
- Data Visualization
Languages

C#

Rust

Python

JavaScript

Java

R
Gen AI platforms

LangChain

Hugging Face

Apache Spark

Gemini

Phi
Frameworks
LangChain

LlamaIndex

PyTorch

Kedro

TensorFlow

Keras
Debugging & Tracing

Langsmith

Langfuse
Vector Databases

PostgreSQL

Chroma

Milvus

Qdrant

Pinecone
DBMS
PostgreSQL

MySQL

MongoDB

CouchDB

Cassandra

Neo4j
Data Visualization

Power BI

Tableau
Languages
C#
Rust
Python
JavaScript
Java
R
Gen AI platforms
LangChain
Hugging Face
Apache Spark
Gemini
Phi
Frameworks
LangChain
LlamaIndex
PyTorch
Kedro
TensorFlow
Keras
Debugging & Tracing
Langsmith
Langfuse
Vector Databases
PostgreSQL
Chroma
Milvus
Qdrant
Pinecone
DBMS
PostgreSQL
MySQL
MongoDB
CouchDB
Cassandra
Neo4j
Data Visualization
Power BI
Tableau



Engineering & Platform Teams
SLOs, error budgets, and observability improve reliability decisions, balancing engineering velocity with service stability.

Product & Commercial
SLO-based reliability commitments support enterprise sales, strengthen trust, and improve incident communication.

Finance & Business Operations
Reliability automation reduces operational toil, frees engineering capacity, and protects revenue through improved uptime.

Customer Experience
Monitoring-driven detection and proactive communication reduce MTTR, outage impact, and customer dissatisfaction.

Legal & Compliance
SLO reporting, incident records, and postmortems provide audit-ready evidence for compliance, SLA, and governance requirements.
Security & Risk
Observability, SIEM integration, and chaos engineering strengthen security and reliability through unified resilience practices.
Sales & Partnerships
SLO dashboards and status pages provide reliability transparency, building trust and supporting enterprise due diligence.
Executive Leadership
Reliability metrics, error budgets, and incident trends provide evidence-based insights for infrastructure investment decisions.


SRE Foundation Programme
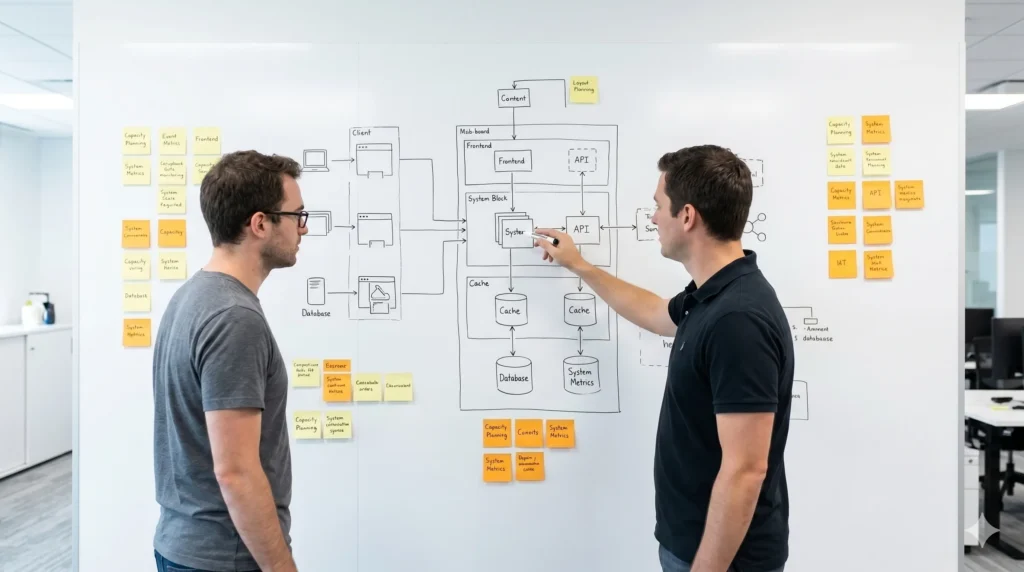
End-to-end SRE implementation covering SLI/SLOs, observability, alerting, incident management, on-call operations, and reliability reviews. Establishes a measurable, proactive reliability practice that improves service performance and operational resilience.

Observability Platform Implementation
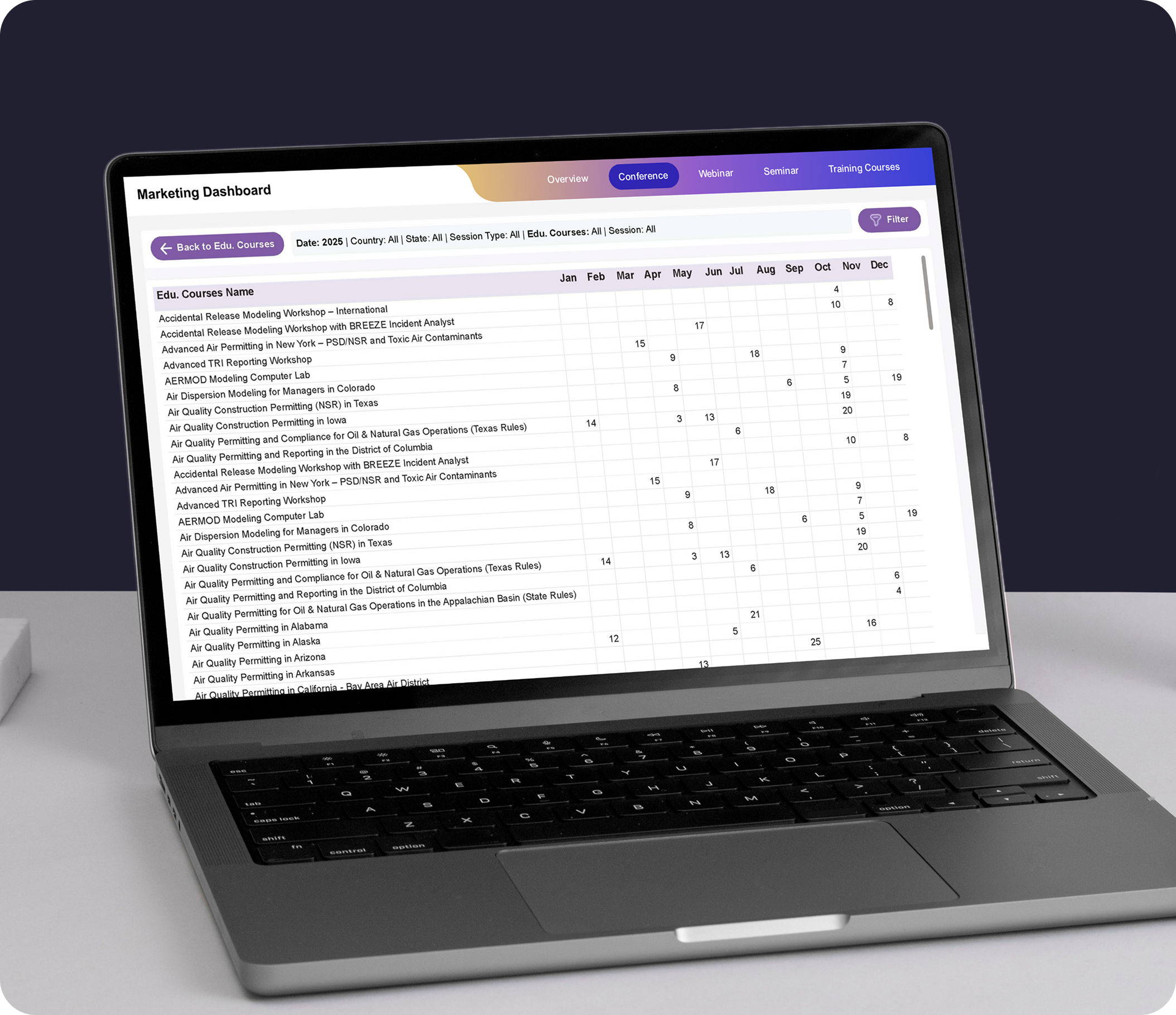
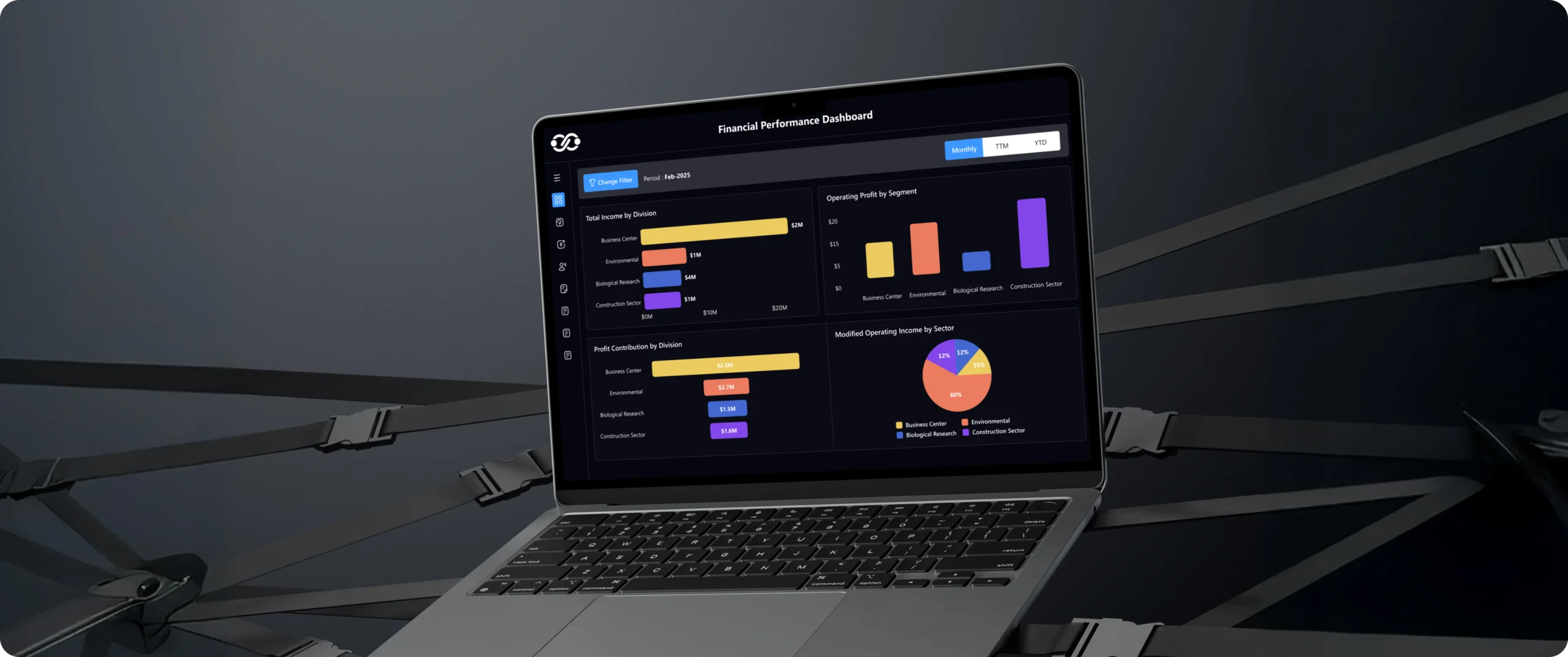
Full-stack observability with metrics, logs, tracing, and OpenTelemetry across applications and infrastructure. Grafana, Datadog, or similar platforms are integrated with SLO-driven dashboards, delivering actionable visibility and faster incident response.

SLO & Error Budget Programme
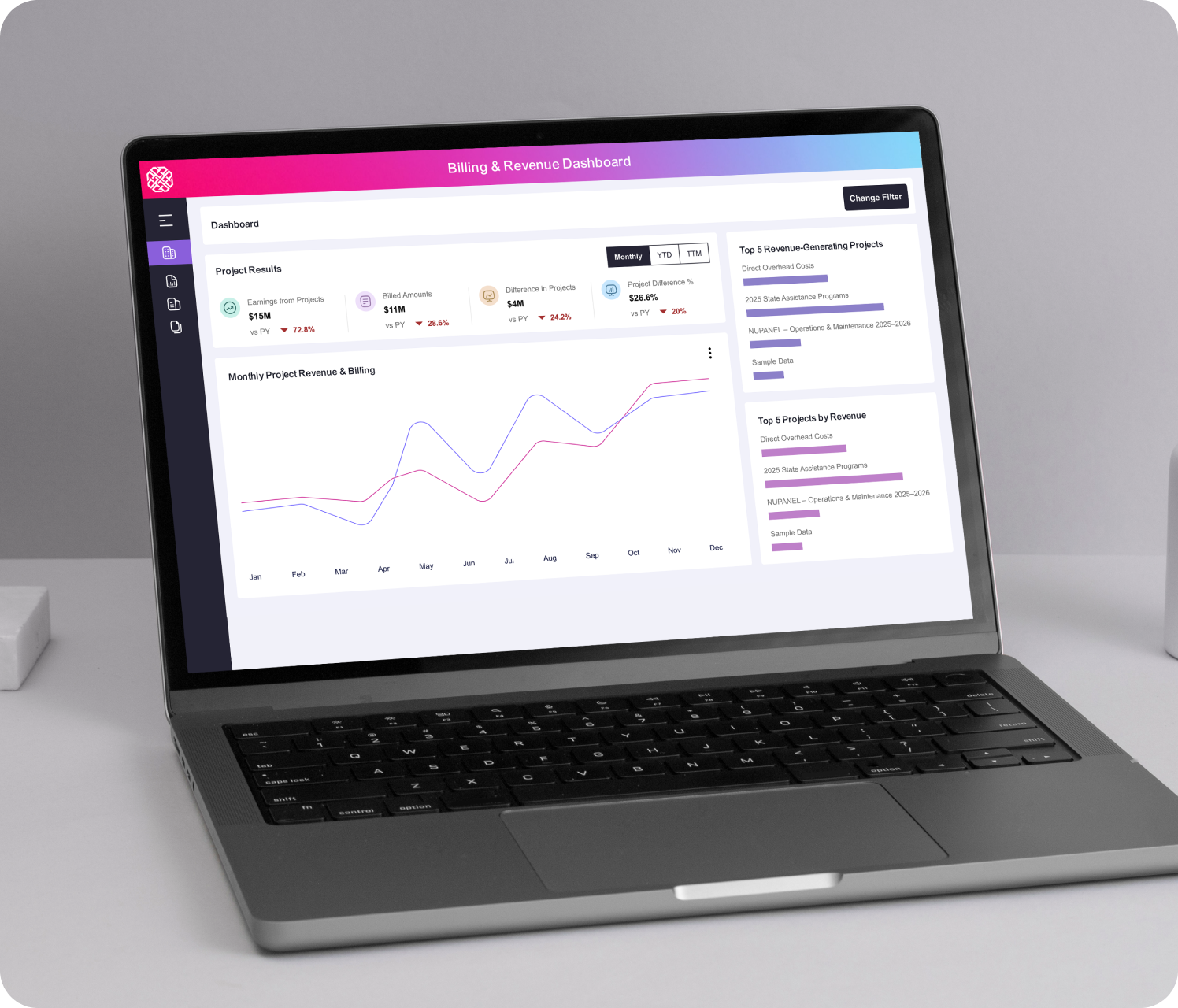
SLI and SLO workshops, error budget policies, burn-rate alerting, and reliability dashboards. Creates a measurable framework linking engineering decisions to user experience, with clear visibility into reliability performance and risk.

Incident Management Transformation
Incident management frameworks with severity models, incident command, communications, post-incident reviews, and improvement backlogs. Establishes a structured, learning-focused approach that reduces incident frequency and accelerates recovery.
Toil Elimination Programme
Toil assessments, automation roadmaps, runbook automation, self-healing systems, and self-service platforms reduce repetitive operational work. Frees engineering capacity for reliability improvements, innovation, and product development.
Chaos Engineering Programme
Chaos engineering programmes design and execute controlled failure tests to validate failover, redundancy, retries, and circuit breakers. Identifies resilience gaps early, ensuring systems perform as expected before real production failures occur.
Internal Developer Platform
Developer platforms with Backstage, service catalogues, golden path templates, self-service deployments, and reliability guardrails. Enables team autonomy while maintaining consistent operational standards, governance, and production reliability.
SRE Managed Advisory Retainer
Ongoing SRE advisory covering SLO reviews, error budgets, chaos engineering governance, observability optimisation, and reliability maturity assessments. Provides specialist expertise to sustain reliability improvements as systems and teams scale.
")