





Let’s Talk Business!
+1 817 380 5522
Let’s Connect


- All
- Languages
- Gen AI platforms
- Frameworks
- Debugging & Tracing
- Vector Databases
- DBMS
- Data Visualization
Languages

C#

Rust

Python

JavaScript

Java

R
Gen AI platforms

LangChain

Hugging Face

Apache Spark

Gemini

Phi
Frameworks
LangChain

LlamaIndex

PyTorch

Kedro

TensorFlow

Keras
Debugging & Tracing

Langsmith

Langfuse
Vector Databases

PostgreSQL

Chroma

Milvus

Qdrant

Pinecone
DBMS
PostgreSQL

MySQL

MongoDB

CouchDB

Cassandra

Neo4j
Data Visualization

Power BI

Tableau
Languages
C#
Rust
Python
JavaScript
Java
R
Gen AI platforms
LangChain
Hugging Face
Apache Spark
Gemini
Phi
Frameworks
LangChain
LlamaIndex
PyTorch
Kedro
TensorFlow
Keras
Debugging & Tracing
Langsmith
Langfuse
Vector Databases
PostgreSQL
Chroma
Milvus
Qdrant
Pinecone
DBMS
PostgreSQL
MySQL
MongoDB
CouchDB
Cassandra
Neo4j
Data Visualization
Power BI
Tableau



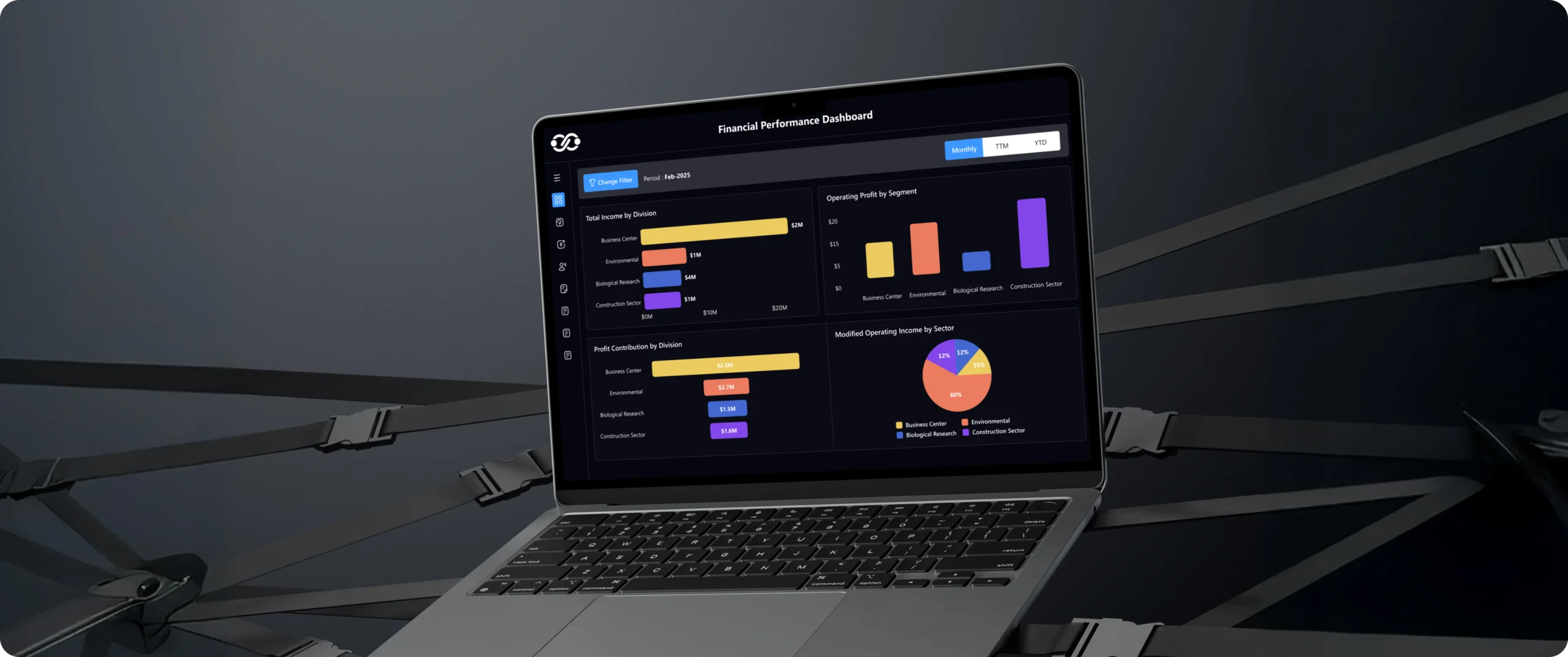
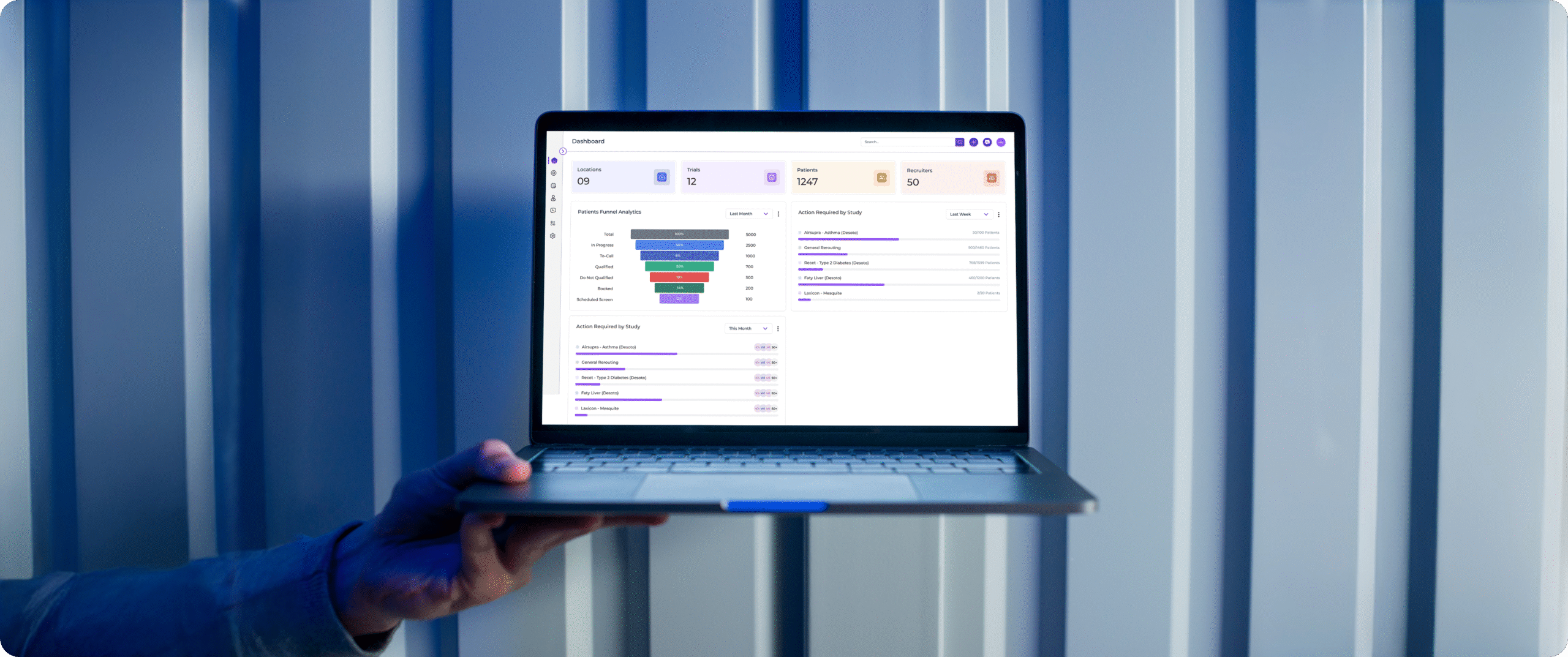
Operations & Supply Chain
Real-time inventory, supplier, and logistics visibility improving forecasting and proactive supply chain exception management.

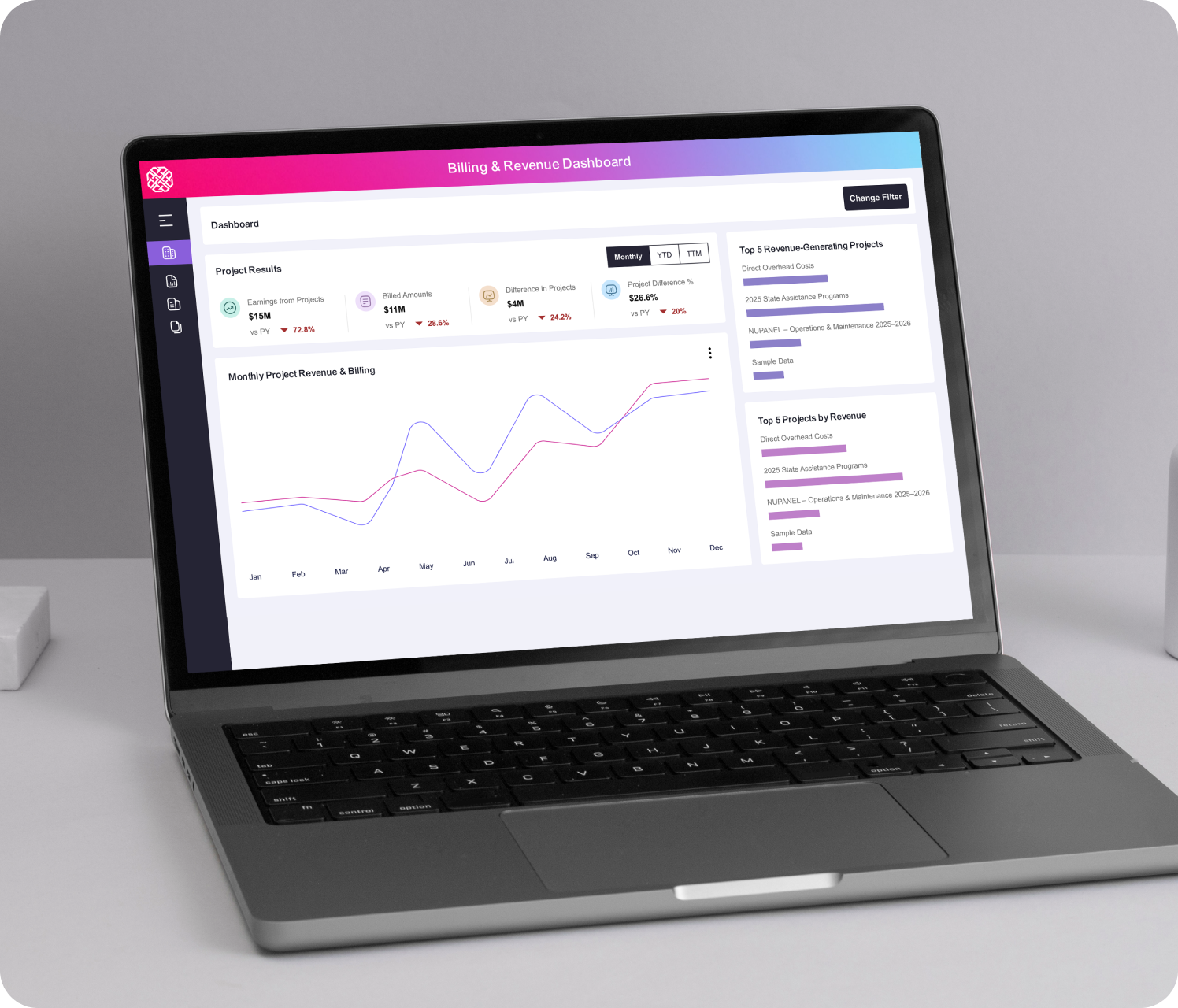
Finance & Accounting
Automated financial reporting, reconciliation, and close processes accelerating month-end visibility and operational accuracy.

Risk & Compliance
Regulatory data governance with lineage, audit trails, and compliance monitoring for GDPR, HIPAA, SOX, and Basel III.

Commercial & Sales
Customer 360 analytics, CRM data unification, and revenue intelligence creating a single source of truth across teams.

Manufacturing & Engineering
IoT analytics, predictive maintenance, and OEE dashboards connecting real-time factory data to enterprise decision systems.
Healthcare & Life Sciences
Clinical data integration, EHR analytics, and patient cohort pipelines built for HIPAA, GDPR, and 21 CFR Part 11 compliance.
IT & Engineering
Telemetry pipelines, observability platforms, and log analytics improving system reliability, visibility, and incident response efficiency.
Marketing & Customer Analytics
First-party data platforms, customer journey analytics, and attribution pipelines enabling data-driven marketing performance optimization.


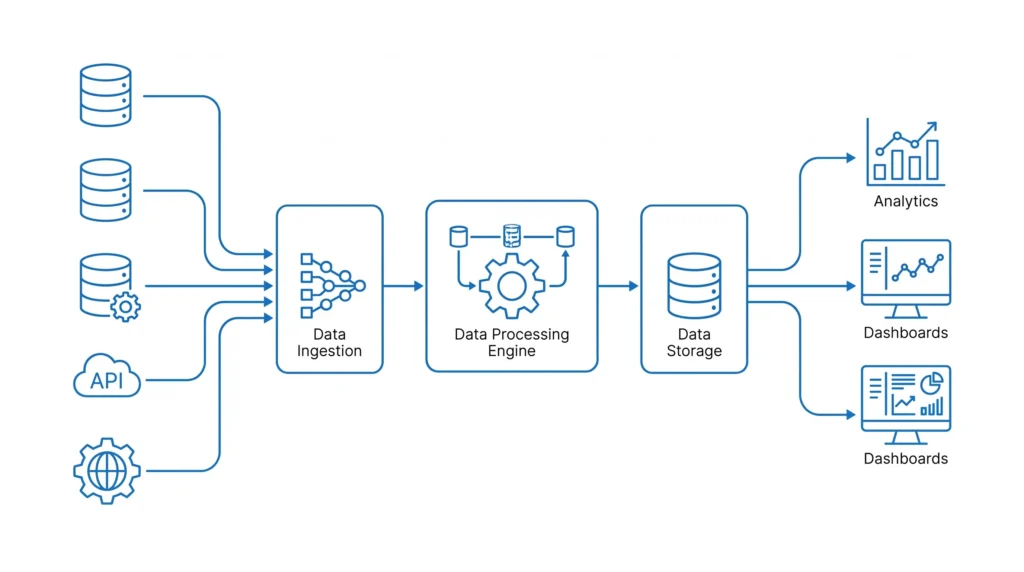
Enterprise Data Lakehouse Platforms
Unified data platforms consolidating structured, semi-structured, and unstructured data into a single governed lakehouse - eliminating the data lake and data warehouse sprawl that forces downstream teams to maintain costly, fragile data copies.

Real-Time Operational Data Platforms
Streaming infrastructure processing transactional, IoT, and event data in real time - powering live fraud detection, dynamic pricing, operational alerting, and customer personalisation at the latency and throughput enterprise use cases demand.

Cloud Data Warehouse Modernisation
End-to-end migration from legacy on-premises data warehouses to Snowflake, BigQuery, or Databricks - including schema translation, historical data migration, pipeline re-engineering, BI reconnection, and post-migration performance tuning.

Customer Data Platforms & Customer 360
Identity resolution, customer data unification, behavioural event pipelines, and Customer 360 data products - giving commercial, marketing, and CX teams a single, trustworthy view of every customer interaction across channels and systems.
Enterprise Data Governance Platforms
Data catalogue implementation, automated lineage tracking, data quality scoring, PII discovery and classification, and access policy enforcement - delivering the governed data foundation required for regulatory compliance, AI readiness, and executive trust.
LLMOps Infrastructure for GenAI
Operational infrastructure for your production GenAI applications - prompt versioning, LLM evaluation pipelines, RAG accuracy monitoring, hallucination detection, token cost tracking, and automated quality assurance - managed with the same rigour as your traditional ML production systems.
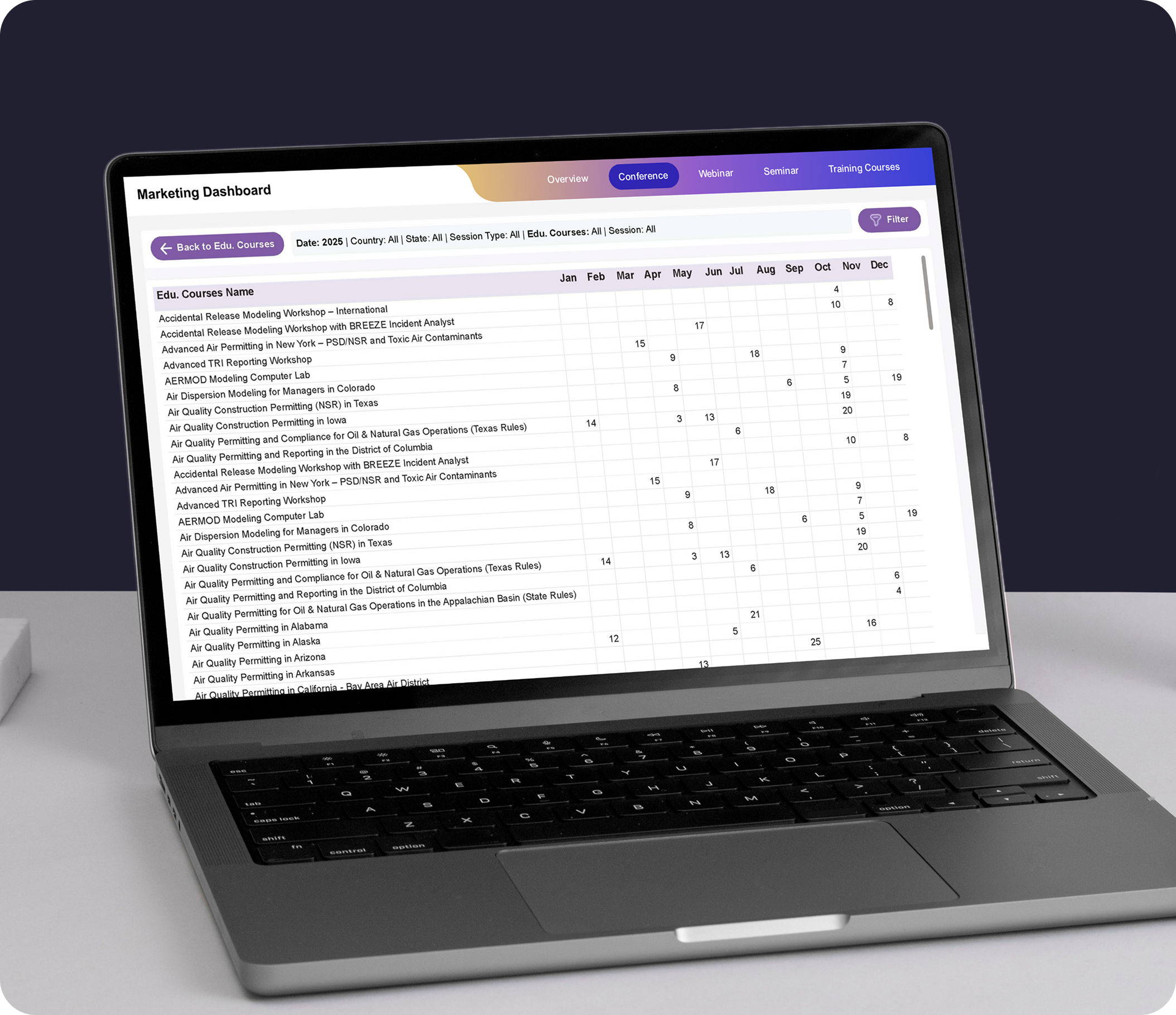
DataOps & Self-Service Analytics Infrastructure
Automated pipeline CI/CD, data contract frameworks, semantic layer implementation, and self-service analytics tooling - enabling business teams to access trusted data without engineering dependency on every query or report.
IoT & Time-Series Data Platforms
High-throughput IoT data ingestion, time-series database design, sensor data normalisation, and operational analytics pipelines - connecting manufacturing, energy, and logistics operational data to enterprise BI and AI systems.
Regulatory & Compliance Data Infrastructure
Automated regulatory reporting pipelines, audit trail data architecture, data residency enforcement, and compliance monitoring platforms - reducing manual regulatory reporting burden while improving accuracy and submission timeliness.