





Let’s Talk Business!
+1 817 380 5522
Let’s Connect

- All
- Languages
- Gen AI platforms
- Frameworks
- Debugging & Tracing
- Vector Databases
- DBMS
- Data Visualization
Languages

C#

Rust

Python

JavaScript

Java

R
Gen AI platforms

LangChain

Hugging Face

Apache Spark

Gemini

Phi
Frameworks
LangChain

LlamaIndex

PyTorch

Kedro

TensorFlow

Keras
Debugging & Tracing

Langsmith

Langfuse
Vector Databases

PostgreSQL

Chroma

Milvus

Qdrant

Pinecone
DBMS
PostgreSQL

MySQL

MongoDB

CouchDB

Cassandra

Neo4j
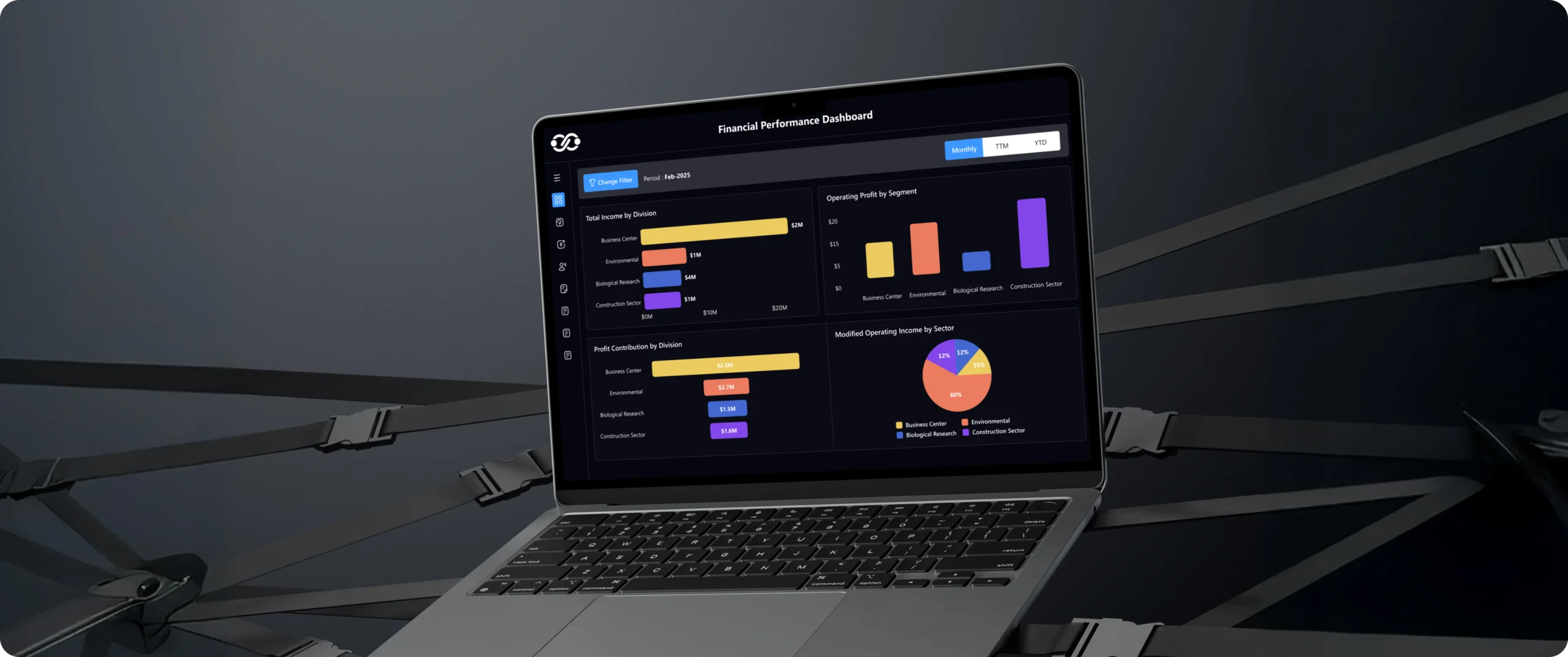
Data Visualization

Power BI

Tableau
Languages
C#
Rust
Python
JavaScript
Java
R
Gen AI platforms
LangChain
Hugging Face
Apache Spark
Gemini
Phi
Frameworks
LangChain
LlamaIndex
PyTorch
Kedro
TensorFlow
Keras
Debugging & Tracing
Langsmith
Langfuse
Vector Databases
PostgreSQL
Chroma
Milvus
Qdrant
Pinecone
DBMS
PostgreSQL
MySQL
MongoDB
CouchDB
Cassandra
Neo4j
Data Visualization
Power BI
Tableau



Manufacturing & Operations
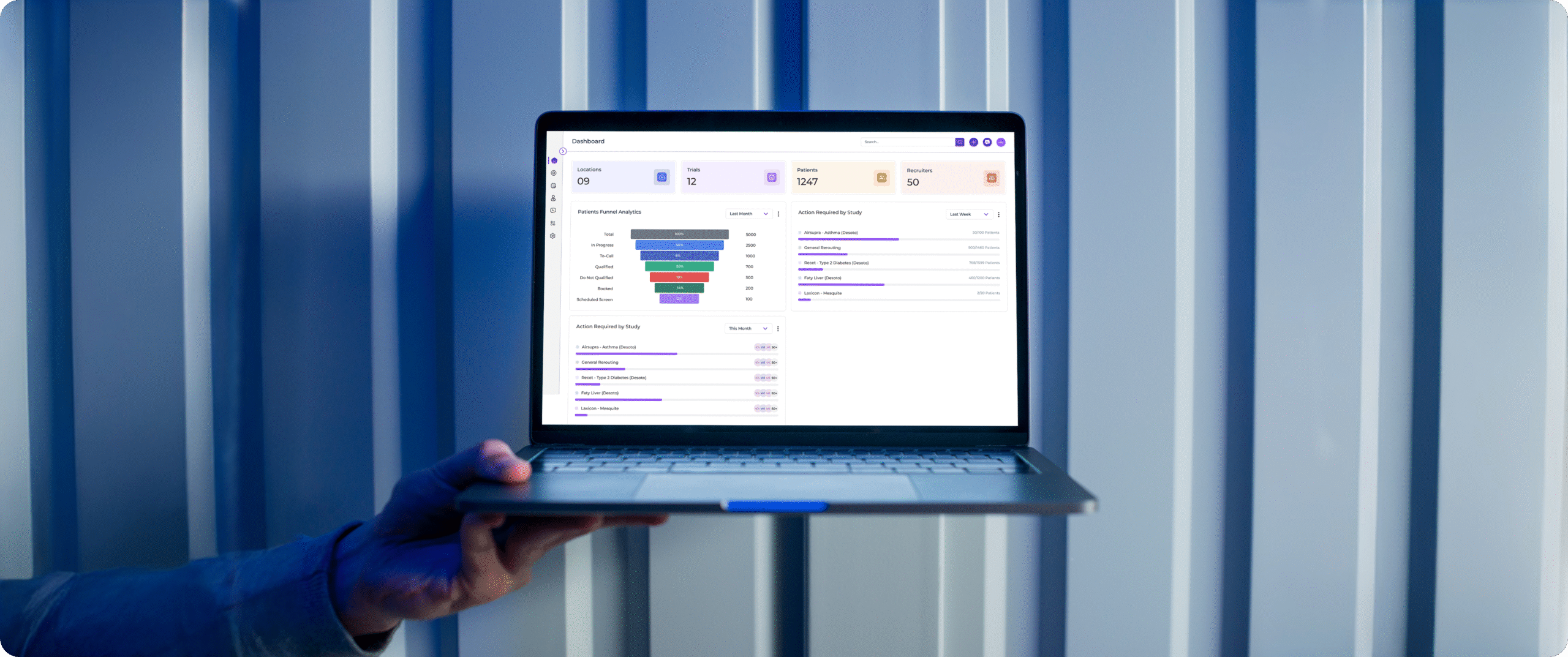
AI-powered MLOps for predictive maintenance, quality inspection, and forecasting with drift monitoring and compliance-ready governance.

Financial Services
AI-powered MLOps for fraud, credit risk, and AML models with explainability, retraining, and audit-ready compliance governance.

Healthcare & Life Sciences
HIPAA-aligned MLOps for clinical AI with audit-ready governance, model traceability, and Epic EHR integration.

Energy & Utilities
AI-powered MLOps for asset prediction and energy forecasting with drift monitoring, retraining, and compliance-ready governance.

Retail & E-commerce
AI-powered MLOps pipelines for pricing, forecasting, and recommendation models enabling rapid, automated retail model updates.
Logistics & Supply Chain
AI-powered MLOps for logistics forecasting and inventory optimization with automated retraining and real-time performance monitoring.


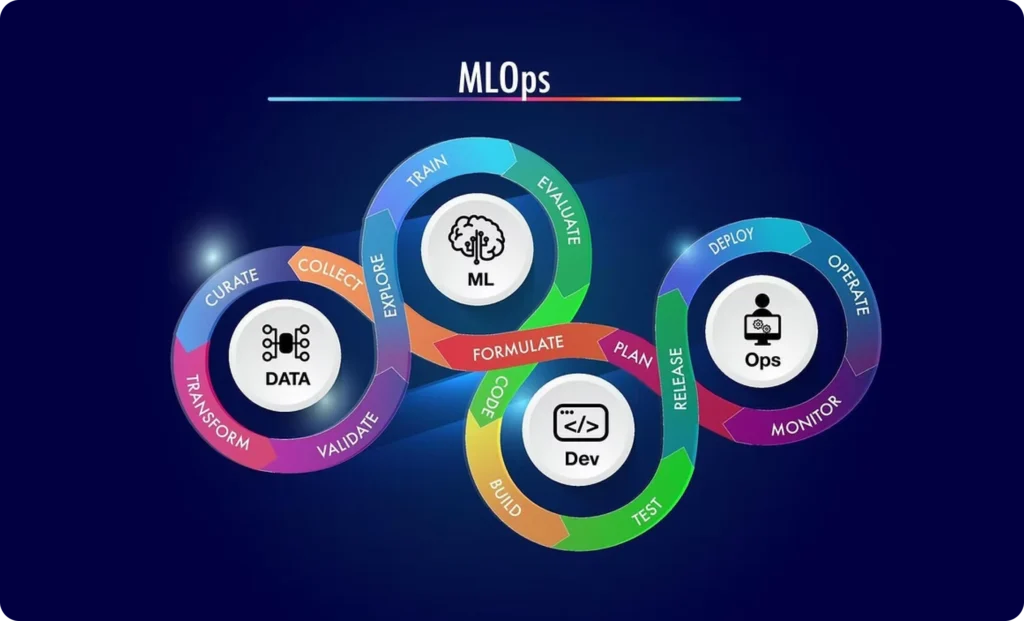
Enterprise ML Platform Build
End-to-end MLOps platform design and implementation - pipeline orchestration, feature store, model registry, CI/CD, monitoring, and governance - built on your cloud environment (AWS, Azure, or GCP) and integrated with your existing data platform, security policies, and operational tooling.

MLOps Modernisation Programme
Assessment and modernisation of existing ad-hoc or fragmented ML operations - migrating notebook-based workflows to automated pipelines, implementing model registry and versioning, deploying monitoring infrastructure, and establishing CI/CD practices across your current model portfolio.

Workplace SafProduction Model Monitoring & Alerting Systemety Monitoring
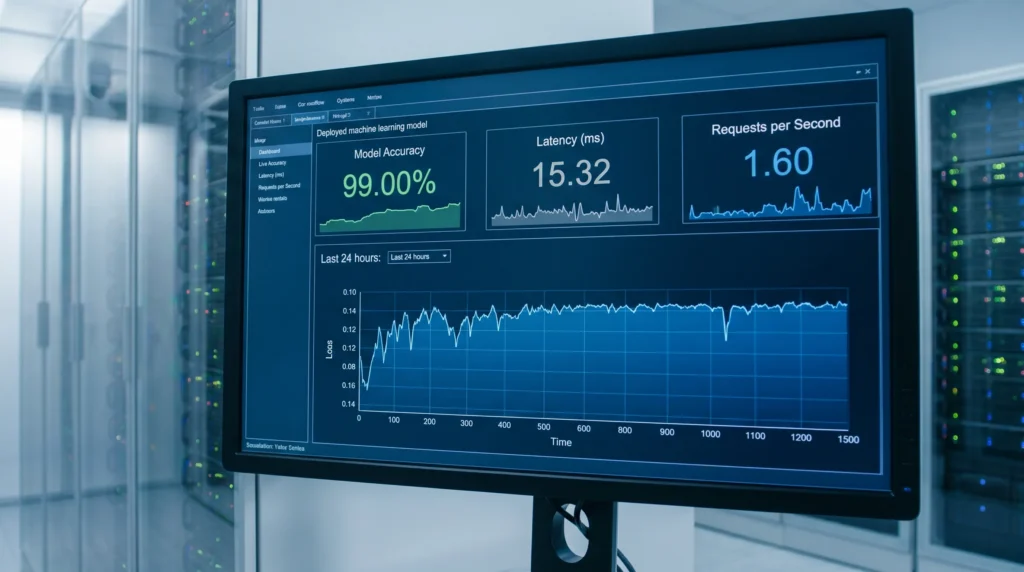
Comprehensive monitoring implementation across your production model fleet - data drift, feature drift, prediction drift, and business KPI tracking - with automated alerting, escalation workflows, and integration into your existing operational dashboards and incident management systems.

Automated Retraining Infrastructure
Design and implementation of automated retraining pipelines for your production models — drift-triggered and schedule-based retraining, automated evaluation against holdout data, quality gate enforcement, and controlled redeployment with rollback capability across your entire production model portfolio.
Feature Store Implementation
Enterprise feature store design and deployment - centralised feature computation, versioning, and serving for training and real-time inference - eliminating training-serving skew, reducing feature engineering duplication, and enabling consistent feature governance across your data science organisation.
LLMOps Infrastructure for GenAI
Operational infrastructure for your production GenAI applications - prompt versioning, LLM evaluation pipelines, RAG accuracy monitoring, hallucination detection, token cost tracking, and automated quality assurance - managed with the same rigour as your traditional ML production systems.
MLOps for Regulated Industries
Compliance-aligned MLOps implementation for financial services, healthcare, manufacturing, and energy - model cards, data documentation, evaluation reports, bias monitoring, explainability integration, and audit-ready governance documentation meeting SEC, FCA, FDA SaMD, and ISO regulatory requirements.
ML Platform Migration
Migration of existing ML infrastructure between cloud platforms or from on-premises to cloud - including pipeline migration, model artefact migration, monitoring infrastructure rebuild, and team capability transfer - with minimal disruption to production model operations during transition.